
The problem this release solves is supply. Vietnamese healthcare LLM work needs question-answer data that starts from grounded medical sources, and that supply has been thin. Meddies QA is one answer to that gap.
The supply problem in Vietnamese medical QA
Good medical question-answer data does not begin with questions. It begins with grounded healthcare information: medical articles, drug references, disease explainers, product descriptions, and patient-facing education material. A model trained on QA that floats free of that base learns answer shapes without learning the domain underneath them. The hard part is the conversion. You have to keep the grounding while turning static reference text into the question-and-answer turns a chat model can train on, and you have to do it at a scale that covers more than one corner of medicine.
Meddies QA takes that conversion as its job. It reorganizes Vietnamese medical question-answer data into five domain groups, exposes it as chat-template QA rows, and adds user-only question-bank configs for teams that want to generate their own answers. The release targets supervised fine-tuning, answer-style adaptation, retrieval-answer experiments, and question-only generation pipelines.
How it was built
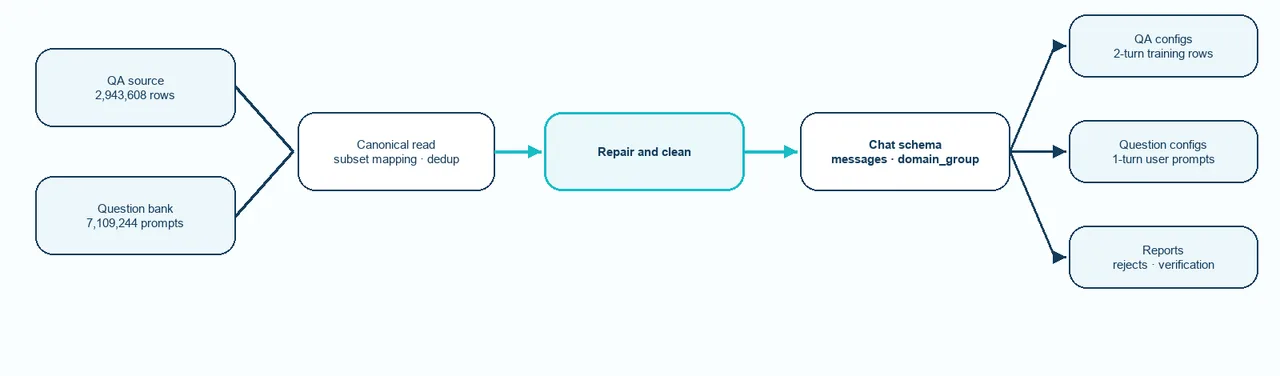
How Meddies QA is built: literature-grounded medical text becomes Vietnamese questions and answers, organized into five domain groups.
The build runs as one argument. Start from literature-grounded medical text. Turn it into Vietnamese questions and answers so a training run can learn domain coverage, answer structure, and medically relevant response patterns from organized examples. Then organize the result so a team can pick its slice by medical area rather than by the source-folder names the original data happened to carry.
That organizing choice is deliberate. The five domain groups are broad on purpose, so users choose compute budgets by medical area instead of by source structure. The release sits between medical-question collections and downstream LLM training. The pipeline takes QA and question-bank inputs, organizes them into training-ready configs, and cuts domain slices for smaller experiments. The answers themselves are machine-generated and cleaned from a source medical corpus, which is the reason the card asks readers to review them before any product, educational, or patient-facing use.
The schema reflects the same restraint. Each row carries messages, question_category, complexity, and domain_group. QA rows hold a user turn then an assistant turn; question rows hold the user turn only. The standalone question, answer, raw_question, and raw_answer fields are dropped from the public training splits, leaving the chat-template field as the one a trainer reads.
What is in it
The repository exposes two config families. The qa_* configs are two-turn chat-template rows with a user question and an assistant answer. The questions_* configs are one-turn user prompts only, included for teams with compute who want to generate or filter their own answers. The default config is qa_all.
| Config | Rows | Message shape | What it gives you |
|---|---|---|---|
qa_all | 2,941,561 | 2 turns | All question-answer pairs for chat-template training. |
qa_clinical_health | 1,009,988 | 2 turns | Disease, prevention, anatomy, mother-and-baby, and general clinical-health QA. |
qa_pharmaceuticals | 1,245,477 | 2 turns | Medicines, active substances, vaccines, excipients, herbs, and drug-reference QA. |
qa_nutrition_supplements | 419,347 | 2 turns | Nutrition, formula, dietary support, and supplement-product QA. |
qa_consumer_health_personal_care | 197,704 | 2 turns | Personal-care, cosmetics, and consumer health product QA. |
qa_medical_devices_equipment | 69,045 | 2 turns | Medical equipment, monitoring devices, and assistive product QA. |
questions_all | 7,109,244 | 1 turn | All user-only prompts for answer generation or distillation workflows. |
questions_clinical_health | 3,428,364 | 1 turn | Disease, prevention, anatomy, mother-and-baby, and general clinical-health prompts. |
questions_pharmaceuticals | 2,035,139 | 1 turn | Medicines, active substances, vaccines, excipients, herbs, and drug-reference prompts. |
questions_nutrition_supplements | 727,001 | 1 turn | Nutrition, formula, dietary support, and supplement-product prompts. |
questions_consumer_health_personal_care | 845,200 | 1 turn | Personal-care, cosmetics, and consumer health product prompts. |
questions_medical_devices_equipment | 73,540 | 1 turn | Medical equipment, monitoring devices, and assistive product prompts. |
Two numbers anchor the scale. The QA side holds 2,941,561 chat-template pairs. The question bank holds 7,109,244 user-only prompts, a deeper well for teams that bring their own answer generation. The gap between them is the point of the split: more questions exist than the release answers, so the prompts can drive distillation or filtering at a larger volume than the supervised pairs allow.
Reading the same data by medical area shows where the mass sits. Pharmaceuticals and clinical health carry most of the QA rows, while devices and equipment form the smallest slice on both sides.
| Domain group | QA rows | Question-bank rows |
|---|---|---|
clinical_health | 1,009,988 | 3,428,364 |
pharmaceuticals | 1,245,477 | 2,035,139 |
nutrition_supplements | 419,347 | 727,001 |
consumer_health_personal_care | 197,704 | 845,200 |
medical_devices_equipment | 69,045 | 73,540 |
The shape across the two columns is not uniform. Clinical health and consumer health both carry far more prompts than answered pairs, so the question bank is where their depth lives. Pharmaceuticals runs closer to balanced. Devices stays small in both. A team picking a slice should read both columns, not just the QA count.
What it enables, and where it stops
The good fits are concrete. Vietnamese medical QA supervised fine-tuning. Domain-specific loading for pharmaceuticals, clinical health, supplements, personal care, or devices. Answer-generation pipelines that start from question-only prompts. Retrieval or evaluation prototypes that need large Vietnamese medical prompts grouped by broad domain. Loading is a single call:
from datasets import load_dataset
qa = load_dataset("Meddies/meddies-qa", "qa_all", split="train")
clinical = load_dataset("Meddies/meddies-qa", "qa_clinical_health", split="train")
questions = load_dataset("Meddies/meddies-qa", "questions_all", split="train")The stops matter as much as the fits. This is a research and training dataset, not a clinical decision system, and not medical advice. The assistant answers are machine-generated and can carry clinical, factual, or style errors, which is why review comes before any patient-facing use. The domain groups are broad routing labels, not expert-reviewed medical ontologies, so they sort rows for compute budgeting rather than certify clinical taxonomy. Rejected rows are kept for review but stay out of the main training configs.
Meddies builds Vietnamese healthcare datasets, evaluation systems, and clinician-facing AI infrastructure, and the design intent here is plain: convert grounded medical text into training-ready Vietnamese QA without losing the grounding. The license is cc-by-nc-4.0, non-commercial. Commercial use needs a conversation first, at [email protected]. The dataset lives at huggingface.co/datasets/Meddies/meddies-qa, and feedback on duplicated rows, unsafe answers, schema issues, or confusing domain placement belongs in a discussion on the repo, with the config name and row evidence attached.