The body is grounded only in the provided README. Returning the finished markdown.
Most clinical LLM evaluation stops at the multiple-choice vignette. Pick the right diagnosis from five options, score the model, move on. That tests one slice of one job. Running a hospital is a wider problem, and almost none of the public Vietnamese training data covers the wider part.
Look at the actual work. Doctors explain pathology to patients in plain Vietnamese. Students learn drug mechanisms before they prescribe. Charge nurses balance bed capacity against surge plans. Administrators read budget variance and write process-improvement memos. A model trained only on MCQ corpora has never seen most of that. The gap is not difficulty. It is coverage. The shape of hospital text, who it is for, and the reasoning behind it are simply absent from vignette datasets.
Meddies Hospital Synthetic is a Vietnamese training set for the rest of that work. It holds 5,214 reasoning tasks across eight hospital competency domains and four audiences, distilled from 444,694 generated samples by a multi-judge rubric. That is a 1.17% acceptance rate. Every row is shaped for chat-format supervised fine-tuning: one <think>...</think> reasoning trace, then a committed final answer, in the style of modern reasoning models.
How a 1.17% acceptance rate happens
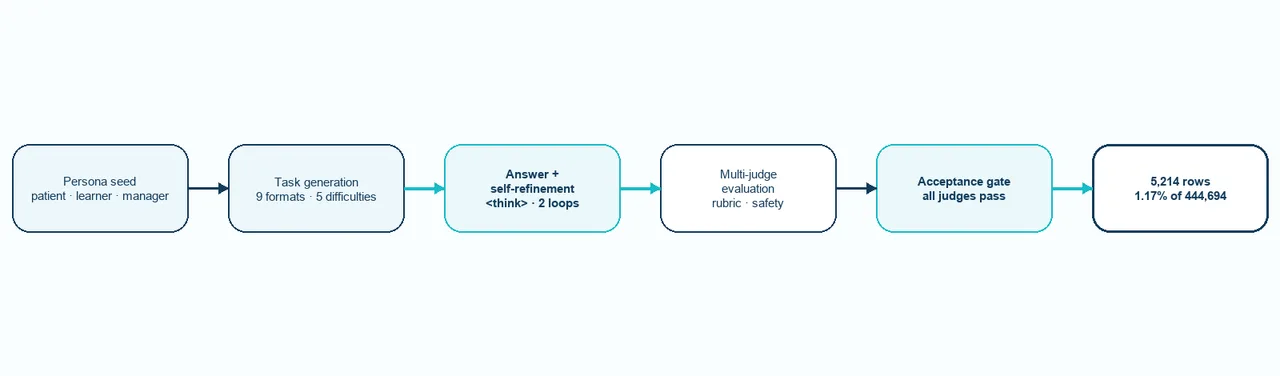
How Meddies Hospital Synthetic is built: persona seeding, task and answer generation, self-refinement, and multi-judge evaluation with safety gates that accept 1.17% of candidates.
The dataset is an acceptance bucket, not a generation log. The argument for trusting it lives in what got thrown away.
Each row starts with a persona seed: a synthetic Vietnamese patient or learner profile that fixes the scene. Audience, social context, medical background. From that seed, an LLM generates a competency-tagged scenario in one of nine format shapes, with explicit perturbation flags written in on purpose. Negation. Irrelevant context. Unit variation. Unreliable narrator. Information overload. The task is built to be hard before any answer exists.
A second pass produces a structured reasoning trace and a draft answer. Then up to two remediation loops critique and rewrite that draft, and the final committed answer is what closes the row. The self-correction is preserved inside the <think> block as natural Vietnamese prose, "Để tôi xem xét lại câu trả lời của mình.", "Let me reconsider my answer", rather than as synthetic XML. A model trained on this learns the move, not the tag.
The last stage is the filter. Domain-specific rubrics, for example DIAGNOSTIC_REASONING, score each answer against safety-pass gates and dimension-level criteria. Only rows that pass every judge reach accepted, and the published subset is exactly that bucket. 444,694 candidates went in. 5,214 came out. The acceptance rate is the dataset's main quality signal, and it is the reason the release is small.
What the rows actually contain
Each row is a Vietnamese clinical or hospital-management task with a fully reasoned answer, and the schema loads directly into a chat-format trainer. The fields carry the structure a fine-tuning run needs.
| Field | Type | What it gives you |
|---|---|---|
messages | list<{role, content}> | Two-turn chat: user prompt, assistant answer with <think> reasoning |
question | string | The user prompt, also available as messages[0].content |
domain | string | One of 8 top-level competency areas (see below) |
category | string | Sub-category leaf (e.g. chief_complaint_analysis, bed_capacity_management) |
audience | string | PATIENT, DOCTOR, STUDENT, or MANAGER — who the answer is for |
difficulty | string | 5 levels from LEVEL_1_BASIC to LEVEL_5_EDGE_CASES |
format_type | string | One of 9 task shapes (long answer, list, MCQ, calculation, procedure, …) |
options | list<struct> or null | MCQ choices when format_type is MCQ_SINGLE or MCQ_MULTIPLE |
perturbation | struct | Adversarial-robustness flags (negation, irrelevant context, unit variation, …) |
id, created_at | string | Row identity and generation timestamp |
The eight domains are uneven, and the imbalance is the honest picture of hospital text. Communication and documentation carries more than half the rows because patient-facing prose is the bulk of what a hospital writes.
| Domain | Rows | What it covers |
|---|---|---|
| Communication & Documentation | 2,605 | Patient education, bad-news delivery, shared decision-making, SOAP notes, discharge summaries, referral letters, handoff |
| Clinical Reasoning | 1,079 | Chief complaint analysis, differentials, pattern recognition, lab/imaging/ECG interpretation, triage and admission decisions |
| Quantitative Skills | 560 | Anthropometric/fluid/pediatric/obstetric calculations, severity and prognostic scores, weight-based and organ-adjusted dosing |
| Medical Sciences | 478 | Disease and drug mechanisms, pharmacokinetics, physiology, immunology, risk-factor and epidemiology basics |
| Hospital Operations | 163 | Bed capacity, staff scheduling, budget variance, accreditation, surge planning, business continuity, legal-risk management |
| Procedures & Diagnostics | 158 | Test and imaging selection, resuscitation, airway, vascular access, emergency procedures |
| Ethics & Safety | 138 | Autonomy, informed consent, treatment refusal, truth-telling, error prevention, medication safety |
| Therapeutics & Management | 33 | Initial management, medication selection, response monitoring, follow-up, chronic-disease management |
Audience is structural, not a label
The four audiences are not a tagging convenience. The audience-domain pairing is built in: a doctor never gets a patient-education task, a manager never gets a clinical-reasoning case. Each row is written for one specific reader, which is what makes audience-conditioned experiments possible. Same domain, different reader, different answer.
| Audience | Rows | Domains it covers |
|---|---|---|
PATIENT | 2,241 | Communication & Documentation (patient-facing prose) |
DOCTOR | 1,772 | Clinical Reasoning, clinical Documentation, Procedures, Therapeutics, Ethics |
STUDENT | 1,038 | Medical Sciences, Quantitative Skills |
MANAGER | 163 | Hospital Operations |
Difficulty spans the full curriculum rather than clustering at the easy or expert ends, and the format mix favours open-ended generation while keeping an MCQ slice for compatibility with vignette-style benchmarks. The numbers below come from the dataset card, not from an independent audit.
| Slice | Rows | % |
|---|---|---|
LEVEL_1_BASIC → LEVEL_2_INTERMEDIATE | 2,545 | 48.8% |
LEVEL_3_ADVANCED → LEVEL_4_EXPERT | 2,309 | 44.3% |
LEVEL_5_EDGE_CASES | 360 | 6.9% |
Open-ended (LONG_ANSWER, LIST_GENERATION, SHORT_ANSWER, CASE_ANALYSIS) | 3,918 | 75.1% |
MCQ (MCQ_SINGLE, MCQ_MULTIPLE) | 354 | 6.8% |
| Calculation, Procedure, Consultation | 942 | 18.1% |
What it enables, and where it stops
This release is built for SFT, not eval. A good fit is fine-tuning a Vietnamese reasoning model to handle hospital work rather than clinical Q&A alone: multi-audience instruction tuning across patient, doctor, student, and manager, hospital-management capability training, mixed open-ended and MCQ supervision, and reasoning-trace alignment through the preserved <think> blocks. The audience tags also support audience-conditioned generation experiments.
The limits are real and stated plainly. This is synthetic data, generated and judged by LLMs. It is not a benchmark, not a prevalence reference, and not a clinical decision tool. The acceptance gate is rubric-based, not clinician-reviewed at the row level, so some rows reflect generator priors: Vietnamese cultural framing, drug-naming conventions, ICD-10 coding habits. The domain mix is uneven by design, and a model fine-tuned on it will need extra balancing if downstream eval weights all domains equally. Hospital Operations is informative but small at 163 rows. Treat it as seed material for further generation, not a finished management corpus.
The dataset lives at huggingface.co/datasets/Meddies/meddies-hospital-synthetic under the cc-by-nc-4.0 license. The most useful thing you can send back is failure: rows where the reasoning is wrong, audience-tone mismatches, missing Vietnamese clinical context, management scenarios that do not match a real Vietnamese hospital, judge-rubric blindspots. For commercial use or collaboration, contact [email protected].