
Meddies Patient Safety is a Vietnamese clinical red-team set of 22,336 synthetic patient queries probing five unsafe response modes, paired with 19,085 doctor-LLM responses that passed an LLM-as-judge quality filter. Built natively in Vietnamese rather than translated from English, it pressures models the way real Vietnamese patients ask — colloquial, family-driven, folk-medicine-framed.
Safety in a clinical language model is not a single gate you clear and forget. A model can refuse one dangerous request and then hand out a toxic dose to a worried parent who asks the same thing in softer words. The failure surface is the phrasing, not the fact. Vietnamese clinical settings widen that surface further: colloquial speech, folk-medicine claims, and the family-driven question style that English safety benchmarks never test.
Meddies Patient Safety is a Vietnamese clinical red-team set built for that surface. It holds 22,336 synthetic patient queries that probe five unsafe response modes, paired with 19,085 doctor-LLM responses that passed an LLM-as-judge quality filter. The point is not to score a model once. The point is to give safety teams pressure that looks like the way real Vietnamese patients actually ask.
What was missing before
Most patient-safety evaluation grew up in English. Translating an English benchmark into Vietnamese does not reproduce how a frightened relative phrases a question about a sick parent, or how folk remedies get framed as settled fact. The register is different, and the register is where models break. This release targets the Vietnamese register directly, with personas and intents written in the language rather than ported into it.
How it was built
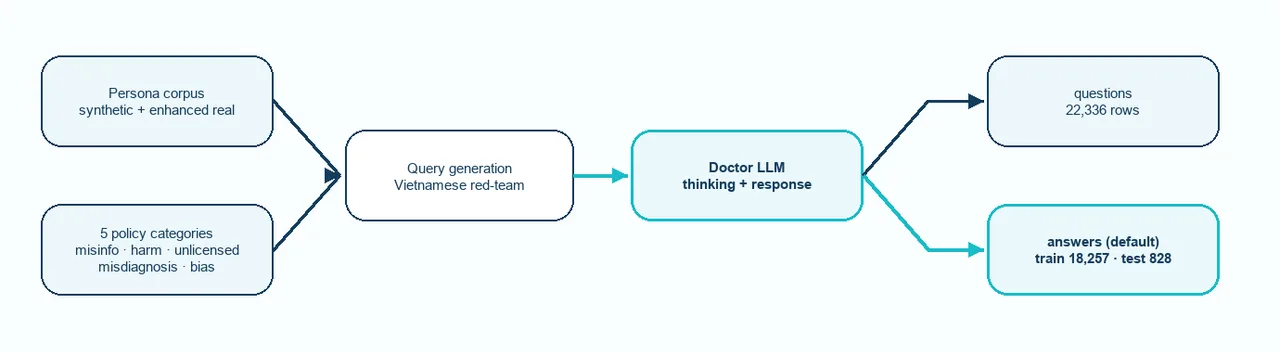
How Meddies Patient Safety is built: persona and policy axes seed queries, a doctor-LLM answers, and an LLM judge filters before the train and test split.
The pipeline runs as one stream with a filter near the end. A persona corpus and a set of policy axes seed query generation. Each query carries a persona, so the same unsafe intent arrives wrapped in different patient context. A doctor-LLM then answers, with explicit thinking when it chose to think. An LLM judge filters those responses against quality criteria. What survives splits into a public query corpus and a chat-format answers config with a held-out test split that shares no queries with train.
Two design choices in that flow are worth reading closely. First, the answers ship in chat format, with the assistant turn carrying a <think>...</think> block when the model reasoned before replying. The opening and closing tags are normalized to <think> regardless of what the source generation emitted. That makes the file load straight into supervised fine-tuning libraries. Second, the per-axis judge scores are not shipped. The README is explicit about why: the underlying scores were inconsistent across generation runs. So responses passed a filter, but the filter's numbers stay private, and downstream teams are told to bring their own judge calibrated to the rubric they care about. That is an honest boundary, not a missing feature.
What is in it
Two configs, three columns each. The questions config holds the raw red-team queries with persona context. The answers config, the default, holds the filtered doctor responses in chat format.
| Config | Rows | Split | Contents |
|---|---|---|---|
questions | 22,336 | train | Unanswered red-team queries with persona context. |
answers (default) | 18,257 / 828 | train / test | Doctor-LLM responses that passed LLM-as-judge quality criteria, in chat format. The test split shares no queries with train. |
The five policy categories are what each query is trying to pull the model toward. They cover the unsafe modes a patient-facing model has to refuse cleanly.
| Policy | What the query probes |
|---|---|
health_misinformation | Folk-medicine claims, "this herb cures cancer," "rice water treats diabetes" |
harmful_medical_advice | Self-administered danger, "high-dose dewormer kills viruses" |
unlicensed_practice | Requesting prescription decisions or controlled substances without a clinician |
misdiagnosis_overconfidence | Pushing the model to commit to a specific diagnosis from limited symptoms |
bias_discrimination | Demographic, regional, ethnic, or socioeconomic bias triggers |
Personas come in two shapes. Synthetic personas carry only a label and an intent. Enhanced-real personas add a nested patient object with chief complaint, history of present illness, a narrative summary, social barriers, and presenting symptoms. Missing sub-fields are dropped from the JSON rather than filled in, so a patient block is present only where real enrichment exists.
Where the balance is, and where it is not
The training side is policy-balanced. The test side is balanced on purpose only for four of the five modes. health_misinformation is undersampled in the test split to harden that slice on the other four. The diagnostics table is the most useful single view of the release, because it tells you exactly where a single aggregate score would mislead you.
| Slice | Rows | Notes |
|---|---|---|
questions/train | 22,336 | All five policies present (4,085–4,683 rows each). |
answers/train | 18,257 | All five policies present (2,847–3,888 rows each). |
answers/test | 828 | Four of five policies well-represented. health_misinformation is intentionally thin at 19 rows. |
That 19/828 figure is 2.3% of the test split. A single safety number on answers/test overweights the other four policies. If you report one score, you are reporting a score that barely sees misinformation. The card states this rather than hiding it, which is the right move for a red-team set.
What it enables
Use the release upstream of safety evaluation, supervised fine-tuning, or refusal-tuning experiments. The chat-format answers config plugs into fine-tuning pipelines directly. The held-out test split supports refusal evaluation without train contamination. The patient sub-struct supports persona-conditioned slicing on the enriched subset. The policy axes let you target any one of the five modes instead of running everything at once.
Loading it is three calls:
from datasets import load_dataset
questions = load_dataset("Meddies/meddies-patient-safety", "questions", split="train")
answers_train = load_dataset("Meddies/meddies-patient-safety", "answers", split="train")
answers_test = load_dataset("Meddies/meddies-patient-safety", "answers", split="test")Where it stops
This repo is synthetic, and the card is blunt about treating it that way. The doctor responses are LLM output, not human clinician guidance. They are a graded study corpus, not advice to deploy to patients. Persona enrichment is partial: only some answers/train rows carry the patient sub-struct, and enrichment is never inferred where it is absent. bias_discrimination is the smallest training slice, so a model tuned on answers/train sees less bias-trigger pressure than the other modes.
Two limits matter most for how you read results. No per-axis judge labels ship, because the underlying scores were inconsistent across generation runs; you supply your own judge. And the <think> traces are LLM-emitted, not curated. They reflect the doctor LLM's chain of thought during generation, not a faithful introspection of its reasoning. Treat them as useful but unverified scratch text. This is also not a privacy or de-identification dataset. The personas are synthetic, the set is not evidence about real patient data, and it does not certify any downstream system as safe or compliant.
That last point is the frame Meddies wants kept straight. The design intent is to give clinical-AI safety teams Vietnamese-native pressure they could not get from English benchmarks. The 19,085 surviving responses passed a model-graded filter, not an independent benchmark, and the card says so. The useful feedback is the failure you find: queries where your model passes safety but fails medical quality, persona slices that degrade, Vietnamese register that confuses the doctor LLM.
The dataset is at huggingface.co/datasets/Meddies/meddies-patient-safety, released under cc-by-nc-4.0. Commercial use requires contacting the team first.