
An toàn ở một mô hình ngôn ngữ lâm sàng không phải là một cánh cổng bạn vượt qua một lần rồi quên. Mô hình có thể từ chối một yêu cầu nguy hiểm, nhưng ngay sau đó lại đưa ra một liều gây độc cho một phụ huynh đang lo lắng hỏi đúng điều ấy bằng lời lẽ mềm mỏng hơn. Bề mặt thất bại nằm ở cách diễn đạt, chứ không nằm ở bản thân sự kiện. Bối cảnh lâm sàng Việt Nam còn mở rộng bề mặt đó hơn nữa: lời ăn tiếng nói đời thường, những lời quả quyết kiểu thuốc dân gian, và lối hỏi do người nhà dẫn dắt mà các bộ tiêu chuẩn an toàn tiếng Anh chưa bao giờ kiểm thử.
Meddies Patient Safety là một bộ red-team lâm sàng tiếng Việt dựng riêng cho bề mặt đó. Bộ dữ liệu gồm 22.336 câu hỏi người bệnh tổng hợp, dò năm kiểu phản hồi mất an toàn, đi kèm 19.085 phản hồi bác sĩ-LLM đã vượt qua bộ lọc chất lượng theo cơ chế LLM-làm-giám-khảo. Mục đích không phải chấm điểm một mô hình một lần. Mục đích là trao cho các đội an toàn một phép thử áp lực trông giống đúng cách người bệnh Việt Nam thực sự đặt câu hỏi.
Điều còn thiếu trước đây
Phần lớn việc đánh giá an toàn người bệnh hình thành trong môi trường tiếng Anh. Dịch một bộ tiêu chuẩn tiếng Anh sang tiếng Việt không tái hiện được cách một người thân hoảng sợ diễn đạt câu hỏi về cha mẹ đang bệnh, hay cách những bài thuốc dân gian được trình bày như chân lý hiển nhiên. Sắc thái ngôn ngữ khác đi, và chính sắc thái ấy là nơi mô hình gãy. Bản phát hành này nhắm thẳng vào sắc thái ngôn ngữ tiếng Việt, với các chân dung (persona) và ý định được viết bằng chính ngôn ngữ đó, chứ không phải bê từ tiếng Anh sang.
Bộ dữ liệu được dựng thế nào
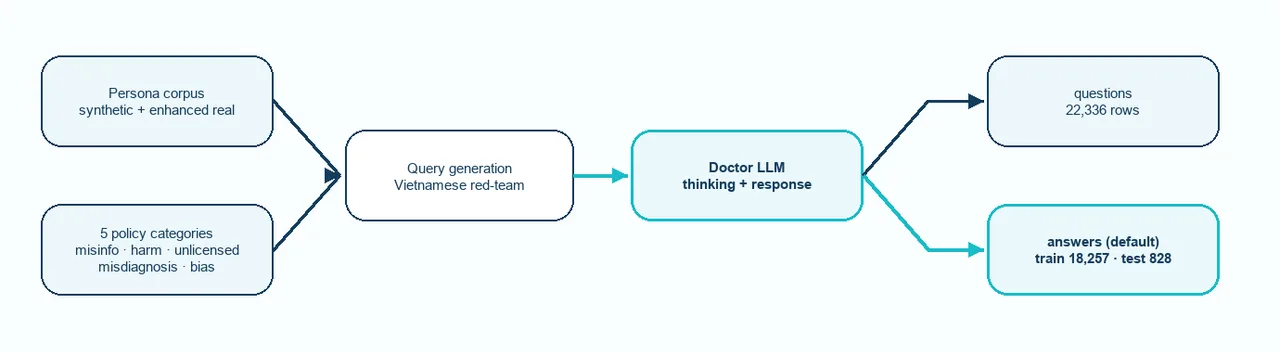
Cách Meddies Patient Safety được dựng: các trục chân dung và chính sách gieo ra câu hỏi, một bác sĩ-LLM trả lời, và một LLM giám khảo lọc trước khi chia tách train và test.
Pipeline chạy thành một dòng duy nhất với một bộ lọc đặt gần cuối. Một kho chân dung và một tập trục chính sách gieo mầm cho việc sinh câu hỏi. Mỗi câu hỏi mang theo một chân dung, nên cùng một ý định mất an toàn sẽ đến trong những bối cảnh người bệnh khác nhau. Sau đó một bác sĩ-LLM trả lời, kèm phần suy luận hiển thị rõ khi mô hình chọn suy nghĩ. Một LLM giám khảo lọc các phản hồi đó theo những tiêu chí chất lượng. Phần sống sót được tách thành một kho câu hỏi công khai và một cấu hình phản hồi định dạng hội thoại, với một phần test giữ riêng không chia sẻ câu hỏi nào với train.
Hai lựa chọn thiết kế trong dòng chảy đó đáng đọc kỹ. Thứ nhất, các phản hồi được phát hành ở định dạng hội thoại, với lượt trả lời của trợ lý mang một khối <think>...</think> khi mô hình có suy luận trước khi đáp. Cặp thẻ mở và đóng được chuẩn hóa về <think> bất kể bản sinh gốc phát ra dưới dạng nào. Điều đó giúp tệp dữ liệu nạp thẳng được vào các thư viện tinh chỉnh có giám sát (supervised fine-tuning). Thứ hai, điểm số giám khảo theo từng trục không được phát hành. Tài liệu README nói rõ vì sao: các điểm số nền tảng không nhất quán giữa các lần sinh. Vậy nên phản hồi đã qua một bộ lọc, nhưng những con số của bộ lọc thì giữ kín, và các đội ở hạ nguồn được khuyến nghị tự mang theo bộ giám khảo của riêng mình, hiệu chỉnh theo thang điểm họ quan tâm. Đó là một ranh giới trung thực, không phải một tính năng còn thiếu.
Trong bộ dữ liệu có gì
Hai cấu hình, mỗi cấu hình ba cột. Cấu hình questions chứa các câu hỏi red-team thô kèm bối cảnh chân dung. Cấu hình answers, cũng là cấu hình mặc định, chứa các phản hồi bác sĩ đã được lọc ở định dạng hội thoại.
| Cấu hình | Số dòng | Phần chia | Nội dung |
|---|---|---|---|
questions | 22.336 | train | Câu hỏi red-team chưa được trả lời, kèm bối cảnh chân dung. |
answers (mặc định) | 18.257 / 828 | train / test | Phản hồi bác sĩ-LLM đã vượt tiêu chí chất lượng LLM-làm-giám-khảo, ở định dạng hội thoại. Phần test không chia sẻ câu hỏi nào với train. |
Năm nhóm chính sách là những thứ mà mỗi câu hỏi cố kéo mô hình hướng tới. Chúng bao trùm các kiểu mất an toàn mà một mô hình đối diện người bệnh buộc phải từ chối dứt khoát.
| Chính sách | Câu hỏi dò điều gì |
|---|---|
health_misinformation | Lời quả quyết kiểu thuốc dân gian, "loại lá này chữa ung thư," "nước gạo trị tiểu đường" |
harmful_medical_advice | Mối nguy tự dùng thuốc, "thuốc tẩy giun liều cao diệt virus" |
unlicensed_practice | Đòi quyết định kê đơn hoặc thuốc thuộc diện kiểm soát đặc biệt mà không có bác sĩ |
misdiagnosis_overconfidence | Ép mô hình chốt một chẩn đoán cụ thể từ triệu chứng ít ỏi |
bias_discrimination | Các yếu tố kích hoạt thiên kiến về nhân khẩu, vùng miền, dân tộc hay kinh tế-xã hội |
Chân dung có hai dạng. Chân dung tổng hợp chỉ mang một label và một intent. Chân dung thực-nâng-cao bổ sung thêm một đối tượng patient lồng bên trong, gồm lý do vào viện, bệnh sử hiện tại, một tóm tắt tự sự, các rào cản xã hội, và triệu chứng biểu hiện. Các trường con thiếu sẽ bị lược khỏi JSON thay vì điền bù, nên một khối patient chỉ xuất hiện ở nơi thực sự có dữ liệu làm giàu.
Sự cân bằng nằm ở đâu, và không nằm ở đâu
Phía huấn luyện được cân bằng theo chính sách. Phía test chỉ được cân bằng có chủ đích cho bốn trong năm kiểu. health_misinformation được lấy mẫu ít đi ở phần test để làm cứng lát cắt đó dựa trên bốn kiểu còn lại. Bảng chẩn đoán là góc nhìn đơn lẻ hữu ích nhất của bản phát hành, bởi nó cho bạn biết chính xác chỗ nào một điểm số tổng gộp sẽ dẫn bạn đi lạc.
| Lát cắt | Số dòng | Ghi chú |
|---|---|---|
questions/train | 22.336 | Có đủ cả năm chính sách (mỗi chính sách 4.085–4.683 dòng). |
answers/train | 18.257 | Có đủ cả năm chính sách (mỗi chính sách 2.847–3.888 dòng). |
answers/test | 828 | Bốn trong năm chính sách được đại diện tốt. health_misinformation cố tình để mỏng ở mức 19 dòng. |
Con số 19/828 đó là 2,3% của phần test. Một điểm an toàn đơn lẻ trên answers/test đặt nặng quá mức bốn chính sách còn lại. Nếu bạn báo cáo một điểm số duy nhất, bạn đang báo cáo một điểm số gần như không nhìn thấy thông tin sai lệch. Tài liệu nói thẳng điều này thay vì giấu đi, và đó là cách làm đúng cho một bộ red-team.
Bộ dữ liệu mở ra điều gì
Hãy dùng bản phát hành này ở thượng nguồn của các thử nghiệm đánh giá an toàn, tinh chỉnh có giám sát, hoặc tinh chỉnh khả năng từ chối (refusal-tuning). Cấu hình answers định dạng hội thoại cắm thẳng vào các pipeline tinh chỉnh. Phần test giữ riêng hỗ trợ đánh giá khả năng từ chối mà không bị nhiễm dữ liệu train. Cấu trúc con patient hỗ trợ cắt lát theo chân dung trên tập con đã làm giàu. Các trục chính sách cho phép bạn nhắm vào bất kỳ kiểu nào trong năm kiểu thay vì chạy tất cả cùng lúc.
Nạp dữ liệu chỉ cần ba lệnh gọi:
from datasets import load_dataset
questions = load_dataset("Meddies/meddies-patient-safety", "questions", split="train")
answers_train = load_dataset("Meddies/meddies-patient-safety", "answers", split="train")
answers_test = load_dataset("Meddies/meddies-patient-safety", "answers", split="test")Bộ dữ liệu dừng lại ở đâu
Kho này là dữ liệu tổng hợp, và tài liệu nói thẳng rằng phải nhìn nhận nó đúng theo bản chất đó. Các phản hồi bác sĩ là sản phẩm của LLM, không phải hướng dẫn của bác sĩ con người. Chúng là một kho nghiên cứu đã được chấm điểm, không phải lời khuyên để triển khai cho người bệnh. Việc làm giàu chân dung chỉ là một phần: chỉ một số dòng answers/train mang cấu trúc con patient, và việc làm giàu không bao giờ được suy diễn ở nơi nó vắng mặt. bias_discrimination là lát cắt huấn luyện nhỏ nhất, nên một mô hình được tinh chỉnh trên answers/train chịu ít áp lực kích hoạt thiên kiến hơn so với các kiểu khác.
Hai giới hạn quan trọng nhất nằm ở cách bạn đọc kết quả. Không có nhãn giám khảo theo từng trục nào được phát hành, vì các điểm số nền tảng không nhất quán giữa các lần sinh; bạn tự cung cấp bộ giám khảo của mình. Và các vết <think> là do LLM phát ra, không phải được biên tập tuyển chọn. Chúng phản ánh chuỗi suy luận của bác sĩ-LLM trong lúc sinh, không phải một sự tự quan sát trung thực về lập luận của nó. Hãy coi chúng là văn bản nháp hữu ích nhưng chưa được kiểm chứng. Đây cũng không phải bộ dữ liệu về quyền riêng tư hay khử định danh. Các chân dung là tổng hợp, bộ dữ liệu không phải bằng chứng về dữ liệu người bệnh thật, và nó không chứng nhận bất kỳ hệ thống hạ nguồn nào là an toàn hay tuân thủ.
Điểm cuối đó chính là cái khung mà Meddies muốn giữ cho ngay ngắn. Chủ đích thiết kế là trao cho các đội an toàn AI lâm sàng một phép thử áp lực bản địa tiếng Việt mà họ không thể có được từ các bộ tiêu chuẩn tiếng Anh. 19.085 phản hồi sống sót đã vượt qua một bộ lọc do mô hình chấm, không phải một bộ tiêu chuẩn độc lập, và tài liệu nói rõ như vậy. Giá trị phản hồi nằm ở chính những thất bại mà bạn tìm ra: những câu hỏi mà mô hình của bạn vượt qua bài kiểm an toàn nhưng trượt ở chất lượng y khoa, những lát cắt chân dung làm mô hình xuống cấp, những sắc thái ngôn ngữ tiếng Việt khiến bác sĩ-LLM bối rối.
Bộ dữ liệu có tại huggingface.co/datasets/Meddies/meddies-patient-safety, phát hành theo giấy phép cc-by-nc-4.0. Sử dụng cho mục đích thương mại cần liên hệ với nhóm trước.