
Một hệ thống AI y tế có thể vượt qua benchmark lâm sàng mà vẫn không thể đưa vào bệnh viện, nếu nó không bảo vệ được thông tin định danh của người bệnh.
Một cái tên bị chép vào prompt. Một số điện thoại lọt vào log phân tích. Một mã hồ sơ đi tiếp vào tập huấn luyện phía sau. Những chuyện đó không phải lỗi sản phẩm nhỏ. Trong y tế, đó là rò rỉ PII/PHI, và thường bị chặn bởi chính sách, hợp đồng, hoặc quy định pháp lý.
Vì vậy khử định danh không nằm ở cuối pipeline như một bước dọn dẹp. Nó nằm bên dưới toàn bộ clinical AI stack. Trước khi mô hình có thể tóm tắt bệnh án, tìm bằng chứng, tạo dữ liệu huấn luyện, hoặc đánh giá câu trả lời, hệ thống phải biết phần nào là định danh cần loại bỏ, phần nào là dữ kiện lâm sàng cần giữ lại.
Phần khó không phải là nhận ra một tên bệnh nhân trong một bệnh án tiếng Anh sạch sẽ. Phần khó là giữ cùng một hành vi trích xuất khi ngôn ngữ đổi, khi tài liệu chuyển từ bảng có cấu trúc sang ghi chú OCR lộn xộn, và khi nhiệm vụ chuyển từ văn bản có tag sang một lượt chat yêu cầu trả về JSON.
Meddies PII được dựng cho khoảng trống đó: một bản phát hành nghiên cứu công khai cho khử định danh lâm sàng đa ngôn ngữ, bắt đầu từ thực tế dữ liệu y tế Việt Nam và mở rộng ra 17 ngôn ngữ.
Vì sao cần thêm một bộ dữ liệu PII
Các nhóm làm AI y tế thường bị kẹt giữa hai lựa chọn đều khó chịu.
Dữ liệu PHI thật phản ánh đúng sự lộn xộn của chăm sóc y tế, nhưng không thể chia sẻ tự do giữa các nhóm. Một bệnh viện có thể dùng nội bộ, nhưng không thể ném lên Hugging Face rồi bảo cộng đồng cùng debug. Còn các bộ NER công khai thì dễ chia sẻ hơn, nhưng nhiều bộ quá hẹp: một ngôn ngữ, một kiểu văn bản, một nhịp câu quen thuộc. Mô hình học cái khuôn, không học nhiệm vụ.
Bài toán này còn khó hơn ở các bệnh viện Việt Nam. Một ghi chú thật có thể trộn tên tiếng Việt, địa chỉ viết tắt, số bảo hiểm y tế, mã hồ sơ bệnh án, tên khoa phòng, số điện thoại người thân, ngày sinh, ngày vào viện, chỉ số xét nghiệm, liều thuốc, và những dòng bán cấu trúc được viết rất nhanh trong lúc chăm sóc. Nếu bộ khử định danh chỉ học từ một mặt phẳng sạch sẽ, nó sẽ vỡ khi gặp bề mặt khác.
Các nghiên cứu về chuyển giao khử định danh lâm sàng đa ngôn ngữ cũng chỉ ra vấn đề tương tự: hệ thống dựa nhiều vào corpora tiếng Anh lớn thường không chuyển trơn tru sang bối cảnh lâm sàng code-mixed hoặc ít tài nguyên hơn. Với Meddies, câu hỏi thực dụng hơn: làm sao tạo một nền dữ liệu đủ công khai để người khác kiểm tra, nhưng vẫn tránh chạm vào hồ sơ người bệnh thật?
Nguyên tắc thiết kế: đổi bề mặt, giữ đích ổn định
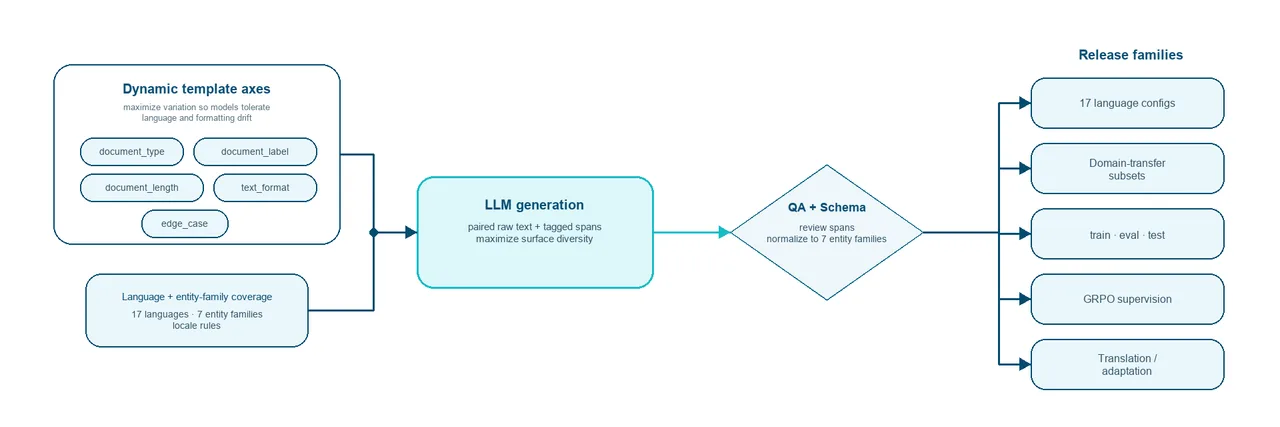
Điểm quan trọng của Meddies PII không phải là “dùng LLM để sinh dữ liệu”. Dùng LLM thì dễ. Sinh ra dữ liệu khiến mô hình học đúng ranh giới khử định danh mới khó.
Chúng mình giữ một đích nhãn nhỏ và ổn định, rồi thay đổi mạnh bề mặt xung quanh nó. Cùng một loại định danh có thể xuất hiện trong bệnh án kể chuyện, phiếu bàn giao, kết quả xét nghiệm, lịch phẫu thuật, hóa đơn, payload FHIR, dòng HL7, bảng markdown, JSON, XML, hoặc một đoạn ghi chú rất xấu sau OCR. Bề mặt thay đổi. Đích trích xuất không được trôi.
Các trục sinh dữ liệu chính:
| Trục | Phạm vi đã xác minh | Vì sao quan trọng |
|---|---|---|
document_type | 16 nhóm trong cả vietnamese và english | Đổi bối cảnh lâm sàng hoặc hành chính mà bộ trích xuất nhìn thấy. |
document_label | 32 giá trị trong vietnamese, 16 trong english | Địa phương hóa lớp nhãn con người đọc, thay vì đóng băng một cách gọi duy nhất. |
document_length | 3 mức: SHORT, MEDIUM, LONG | Tránh để mô hình học một kích thước ghi chú quen thuộc. |
text_format | 10 định dạng bề mặt | Kiểm tra prose, bảng, list, payload có cấu trúc và ghi chú lộn xộn. |
edge_case | 20 giá trị trong vietnamese, 10 trong english | Ép bộ sinh dữ liệu đi vào các ca ít lặp lại hơn. |
label ontology | 7 họ thực thể công khai | Giữ nhiệm vụ trích xuất ổn định khi ngôn ngữ và định dạng thay đổi. |
Bảy họ thực thể là: human_name, date, id_number, phone_number, email_address, address, và company_name.
Đây là một taxonomy cố ý hẹp. Một danh sách nhãn dài có thể nhìn “đầy đủ” hơn, nhưng dễ vỡ khi đi qua nhiều ngôn ngữ và kiểu tài liệu. id_number gom các mã hồ sơ bệnh án, mã bảo hiểm, số tài khoản, giấy phép, mã thiết bị và các định danh hành chính tương tự. company_name gom bệnh viện, phòng khám, khoa phòng, công ty bảo hiểm, cơ quan, trường học, hoặc nơi làm việc khi chúng đóng vai trò định danh tổ chức.
Quan trọng hơn: không phải mọi dữ kiện nhạy cảm đều là nhãn PII trong bản phát hành này. Tuổi, huyết áp, xét nghiệm, liều thuốc, triệu chứng, chẩn đoán và thuốc đang dùng không thuộc bảy nhãn trên. Chúng có thể nhạy cảm về mặt lâm sàng, nhưng nếu một de-identifier xóa sạch creatinine 86 µmol/L hoặc metformin 500 mg, bản ghi sau khử định danh sẽ mất giá trị cho hệ thống phía sau.
Nói ngắn gọn: bỏ sót ngày sinh là lỗi riêng tư. Xóa nhầm liều thuốc là lỗi lâm sàng. Một lớp khử định danh tốt phải tránh cả hai.
Bản phát hành này chứa gì
Kho Hugging Face được tổ chức thành nhiều cấu hình, không phải một khối dữ liệu phẳng. Các nhóm chính trong phạm vi bài này:
| Nhóm dữ liệu | Số dòng | Cấu hình | Dùng để làm gì |
|---|---|---|---|
| Tài liệu gắn nhãn theo ngôn ngữ | 831.746 | vietnamese, english, chinese, japanese, korean, thai, french, german, spanish, portuguese, russian, indonesian, filipino, malay, burmese, laos, tamil | Văn bản y tế và hành chính tổng hợp, có bản đã gắn nhãn, bản thô, và JSON nhãn quy chuẩn. |
| Tập tiếng Anh để kiểm tra chuyển miền | 63.160 | nvidia-health, nvidia-non-health | Hồ sơ tiếng Anh có cấu trúc và phi cấu trúc, giữ cùng đích nhãn để kiểm tra domain shift. |
| Gói huấn luyện và đánh giá hỗn hợp | 76.160 | train, eval, test | Các lát hướng nhiệm vụ, có xuất xứ source, dùng cho huấn luyện, đánh giá và smoke test. |
| Giám sát dạng instruction / GRPO | 7.100 | grpo-train, grpo-hard-train | Prompt trích xuất kiểu chat, đáp án JSON đã chuẩn hóa, và văn bản nguồn. |
| Góc nhìn dịch thuật / thích ứng | 10.000 | vietnamese-translated | Các bản ghi thích ứng tiếng Việt với input, text, raw, label, và số token. |
Những con số này không nên cộng lại thành một “tổng số dòng” duy nhất. Một vài cấu hình là góc nhìn dẫn xuất trên các họ khác, không phải corpora độc lập. Riêng cấu hình tiếng Việt có 45.921 dòng. Mỗi bản ghi ngôn ngữ mang ba dạng giám sát: text có tag dạng [value]<label>, raw đã bỏ tag, và label là JSON quy chuẩn theo bảy họ thực thể.
Bản phát hành này phù hợp nhất để nghiên cứu hành vi khử định danh, tạo evaluator, dựng challenge set, kiểm tra dịch chuyển định dạng, và fine-tune extractor theo ngữ cảnh bệnh viện. Nó không phải chứng nhận rằng một hệ thống downstream đã riêng tư hay tuân thủ.
Chúng mình kiểm soát lỗi như thế nào
Dữ liệu tổng hợp rất dễ sinh, và cũng rất dễ nhiễm bẩn.
Một nhãn sai có thể dạy mô hình sai ranh giới. Một mẫu tiếng Lào lẫn chữ Trung có thể làm lát ít tài nguyên trông lớn hơn thực tế. Một giá trị không có trong văn bản nguồn có thể thưởng nhầm cho mô hình vì bịa ra một định danh nghe có vẻ hợp lý.
Vì vậy pipeline không dừng ở bước sinh dữ liệu:
- Prompt sinh dữ liệu định rõ ngôn ngữ, loại tài liệu, độ dài, định dạng, quy tắc địa phương và edge case.
- Quy tắc locale chặn các lỗi dễ thấy như rò ngôn ngữ, tên, địa chỉ hoặc định dạng không thuộc bối cảnh đang sinh.
- Validator schema loại tag sai, nhãn lạ, span rỗng, nội dung lặp, số điện thoại quá ngắn, hoặc giá trị không xuất hiện trong nguồn.
- Chuẩn hóa nhãn gom các biến thể nhỏ về bảy họ công khai.
- Model review kiểm tra tính đúng của thực thể, nhãn, date overreach, giá trị bịa và span bị bỏ sót.
- Human review tập trung vào một lát tiếng Việt 1.000 mẫu. Toàn bộ dữ liệu đa ngôn ngữ còn lại dựa vào validator và model review, không phải rà soát thủ công từng dòng.
Điểm cuối cùng cần nói thẳng. Chúng mình không tuyên bố đã có adjudication thủ công hoàn chỉnh cho mọi ngôn ngữ. Một bản phát hành công khai tốt hơn một tuyên bố đẹp: người khác có thể tải về, kiểm tra, phản biện, và gửi failure case.
Mô hình nhỏ đi cùng bản phát hành
Bên cạnh dataset, chúng mình cũng huấn luyện một extractor nhỏ cùng tên từ LiquidAI/LFM2-350M. Lý do chọn mô hình nhỏ khá đơn giản: bài toán này không cần một generalist khổng lồ để “hiểu y khoa”. Nó cần đọc văn bản, chép đúng span có trong nguồn, và trả về JSON ổn định.
Điều đó hợp với các thử nghiệm chạy gần dữ liệu hơn: GPU phổ thông, inference nội bộ, và về lâu dài là các đường ONNX / browser. Lớp riêng tư càng nằm gần dữ liệu gốc thì càng ít phải gửi định danh đi xa chỉ để… phát hiện định danh. Nghe hơi trớ trêu, nhưng nhiều pipeline AI hiện nay đúng là dễ rơi vào cảnh đó.
Model card hiện báo cáo entity-level exact match trên các lát eval và test: một dự đoán chỉ đúng khi cả giá trị được chép và nhãn đều khớp. Cách chấm này hợp với khử định danh hơn token overlap, vì downstream thường tiêu thụ cặp (value, label) chứ không tiêu thụ “vùng gần đúng”.
| Chỉ số | Bộ dữ liệu / lát | Kết quả | Cách đọc |
|---|---|---|---|
| F1 thực thể | Meddies/meddies-pii / eval | 0.8110 | Lát validation đa ngôn ngữ. |
| Precision | Meddies/meddies-pii / eval | 0.8112 | Chấm khớp chính xác ở cấp thực thể. |
| Recall | Meddies/meddies-pii / eval | 0.8109 | Chấm khớp chính xác ở cấp thực thể. |
| F1 thực thể | Meddies/meddies-pii / test | 0.8380 | Lát test giữ riêng. |
| Precision | Meddies/meddies-pii / test | 0.8116 | Còn có dự đoán thừa cần rà soát. |
| Recall | Meddies/meddies-pii / test | 0.8663 | Model tìm được khá nhiều span mục tiêu. |
| Giá trị bịa | eval / test | 1.31% / 1.35% | Giá trị được sinh ra nhưng không có trong đầu vào. |
Con số F1 0.8380 là tín hiệu tốt, nhưng không nên đọc như giấy phép triển khai. Nó là bằng chứng cho một hành vi trên lát tổng hợp giữ riêng: model thường chép được đúng span mục tiêu, nhưng vẫn còn dự đoán thừa và một tỷ lệ nhỏ giá trị bịa.
Các lớp có hình thái cứng như phone_number và email_address dễ hơn. Các lớp cần ranh giới ngữ nghĩa như human_name, address, và đặc biệt company_name khó hơn. Bảng ngôn ngữ cũng không phẳng: Vietnamese đạt F1 0.8251, trong khi Lao và Russian thấp hơn đáng kể. Đó là lý do chúng mình muốn công bố cả điểm yếu, không chỉ headline.
Những lỗi cần audit trước
Nếu bạn dùng Meddies PII, đừng bắt đầu bằng câu “F1 bao nhiêu?”. Hãy bắt đầu bằng câu “nó sai theo kiểu nào?”.
| Kiểu lỗi | Ví dụ hình thái | Hậu quả |
|---|---|---|
| Bỏ sót định danh | Tên bệnh viện hoặc khoa phòng không được bắt thành company_name. | Định danh tổ chức còn lại trong văn bản và có thể ảnh hưởng audit trail. |
| Gắn nhầm dữ kiện lâm sàng | BP 120/80, creatinine 86 µmol/L, hoặc 500 mg bị xem như id_number hay date. | Văn bản sau khử định danh mất dữ kiện cần cho reasoning. |
| Quá tay với ngày tháng | Ngày vào viện hoặc ngày đo xét nghiệm bị xử lý như ngày sinh. | Timeline chăm sóc bị phá hỏng. |
| Input né tránh | Email viết kiểu nguyen dot an at... hoặc số điện thoại bị tách ký hiệu. | Cần một stress test riêng trước khi nói về coverage. |
| Rò ngôn ngữ | Mẫu tổng hợp của một ngôn ngữ lẫn chữ hoặc cụm từ của ngôn ngữ khác. | Lát dữ liệu nhìn lớn hơn chất lượng thật. |
| Thực thể lồng nhau | Tên khoa nằm trong tên bệnh viện dài hơn. | Schema hiện tại chưa giải quyết span chồng lấp. |
Đây là chỗ dataset công khai có ích. Mỗi nhóm có thể tải dữ liệu, chạy extractor, thêm challenge set theo ngôn ngữ hoặc bệnh viện mình hiểu, rồi kiểm tra lại thay vì tin vào một điểm số chung.
Phạm vi của bản phát hành
Meddies PII không phải sản phẩm redaction hoàn chỉnh. Nó trích xuất span có cấu trúc để đưa vào một workflow khử định danh. Production redaction vẫn cần chính sách, audit log, kiểm định cục bộ, cơ chế escalation, và kiểm soát triển khai.
Nó cũng không chứng minh dữ liệu tổng hợp giống bệnh viện của bạn. Synthetic data cho chúng ta supervision có thể chia sẻ, nhưng vẫn có thể bóp méo tần suất, văn phong và các mẫu hiếm. Nếu bệnh viện của bạn dùng cách viết tắt riêng, mã bảo hiểm riêng, hoặc tên khoa phòng rất khác, hãy kiểm định trên dữ liệu của bạn trước khi tin extractor.
Và đây không phải taxonomy riêng tư mở rộng. Bảy nhãn là lựa chọn có chủ đích để giữ schema nhỏ, dễ audit, và dễ chuyển qua nhiều ngôn ngữ. Taxonomy rộng hơn có thể đến sau, nhưng không nên làm hỏng mục tiêu đơn giản khiến bản phát hành này dùng được.
Bắt đầu từ đâu
Nếu bạn làm nghiên cứu, hãy dùng dataset để dựng evaluator, phân tích lỗi theo ngôn ngữ, kiểm tra domain shift, hoặc xây challenge set cho de-identification. Đừng chỉ chạy một điểm F1 chung. Hãy xem lớp nào fail, ngôn ngữ nào fail, định dạng nào fail.
Nếu bạn là đội AI bệnh viện, hãy xem model như một extractor nhỏ có thể đứng trước logging, training, retrieval hoặc agent workflow. Nhưng trước khi đưa vào luồng thật, hãy kiểm định bằng dữ liệu, chính sách và rủi ro của chính bệnh viện bạn.
Bắt đầu ở đây:
- Dataset: Meddies/meddies-pii
- Model: Meddies/meddies-pii
- Playground miễn phí: Meddies/meddies-pii-extractor
- Đường ONNX / browser: Meddies/meddies-pii-onnx
Dataset và model được phát hành theo CC-BY-NC-4.0 cho nghiên cứu phi thương mại. Nếu bạn muốn dùng trong sản phẩm thương mại hoặc muốn cùng review một lát ngôn ngữ cụ thể, hãy viết cho chúng mình tại [email protected].